
سازوکار توجه (Attention):
راهکار توجه در یادگیری عمیق برای بهبود عملکرد یک شبکه عصبی برای اجازه دادن به مدل برای توجه روی مهمترین دادههای ورودی در حین تولید پیشبینی استفاده میشود. این راهکار در سال ۲۰۱۵ در مقالهای که توسط Bahdanau نوشته شده بود، برای حل مسئلهی ترجمه ماشینی معرفی شد. سازوکار توجه مدل را قادر می سازد تا بر عناصر دقیق عبارت ورودی که برای تولید داده جاری در دنباله خروجی در هر مرحله از فرآیند رمزگشایی مهم هستند، تمرکز کند.
در سال ۲۰۱۴، شبکه های عصبی بازگشتی و حافظه کوتاهمدت طولانی بازگشت باشکوهی به عرصه یادگیری ماشین داشتند. اما این مربوط به سالها قبل است، زمانی که تجربه کافی نداشتیم. راهکاری که در گذشته برای و یادگیری توالیها (seq2seq) و ترجمه توالی وجود داشت. اما یکی از مشکلات شبکه های عصبی بازگشتی این است که برای کار با سختافزارها مناسب نیستند. یعنی برای آموزش این شبکهها و اجرای مدل در فضای ابری به منابع بسیار زیادی نیاز داریم و همانطور که میدانیم، با توجه به رشد فزاینده فناوری تبدیل گفتار به نوشتار، فضای ابری ظرفیت کافی را ندارد. شبکه های عصبی بازگشتی، حافظه کوتاهمدت طولانی و شبکههایی که از آنها مشتق شدهاند عمدتاً از پردازش ترتیبی طی زمان استفاده میکنند. اطلاعات بلندمدت قبل از رسیدن به سلول پردازشی فعلی باید به ترتیب از همه سلولها بگذرند. این مسیر به خاطر ضرب چندین باره در اعداد کوچک (کوچکتر از ۰)، به راحتی میتواند مختل شود. این مشکل دلیل ناپدیدشدگی گرادیانها میباشد. شبکهی کدگذار یا Encoder وظیفه دارد که کل رشتهی ورودی را پردازش کرده و اطلاعات آن را در وکتوری با ابعاد بالاتر ذخیره کند. در مرحلهی بعد، این وکتور به شبکهی کدگشا یا Decoder داده میشود تا رشتهی خروجی تولید شود.
بنابراین سازوکار توجه در مدل های یادگیری عمیق برای وزن کردن ویژگیهای ورودی، و توجه بر اساسیترین بخشهای ورودی استفاده می شود.این کار با وزن دادن به داده های ورودی انجام می شود تا مدل برخی از ویژگی های ورودی را بر سایرین اولویت دهد. در نتیجه، مدل میتواند پیشبینیهای دقیقتری را تنها با در نظر گرفتن مهمترین متغیرهای ورودی تولید کند. مکانیسم توجه اغلب در کارهای پردازش زبان طبیعی مانند ترجمه ماشینی استفاده می شود، جایی که مدل باید به بخش های مختلف عبارت ورودی توجه کند تا معنای آن را به طور کامل درک کند و ترجمه مناسب ارائه دهد. “توجه” (Attention) بیان میکند که هنگام تولید خروجی آینده، تا چه اندازه باید به قبل (گذشته) توجه کنیم. شکل زیر نمونه ای ساختار رمزگذار-رمزگشای مبتنی بر توجه را برای ترجمه ماشینی نشان می دهد.
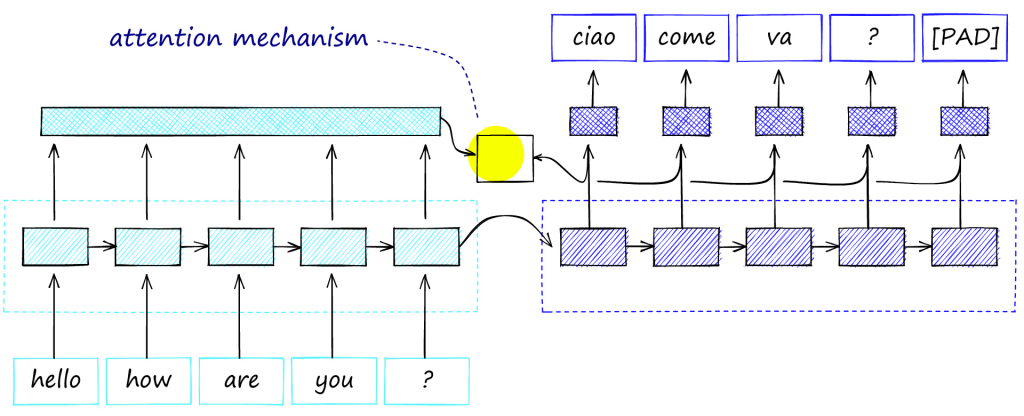
انواع مختلف توجه (Attention):
سازوکار توجه براساس محیطی که در آن مدل توجه استفاده می شود یا بخشهای مربوط به دنباله ورودی که مدل بر آنها تمرکز میکند، متفاوت است. در زیر مهم ترین راهکارهای توجه ذکر شده است که در دوره آموزشی بحث و پیاده سازی می شوند.
- توجه به خود (Self Attention)
- توجه به غیرخود (Cross Attention)
- توجه چندسر (Multi-head Attention)
- توجه نرم (Soft Attention)
- توجه سخت (Hard Attention)
- توجه محلی (Local Attention)
- توجه سراسری (Global Attention)
شبکه ترنسفورمر (Transformer):
شبکه ترنسفورمر از مکانیزم توجه (Attention Mechanism) استفاده میکند که برای اولین بار در سال ۲۰۱۷ معرفی شد. مشکل شبکه های بازگشتی این بود که در آن امکان پردازش موازی وجود نداشت. این مشکل در ترنسفورمر برطرف شده و میتوانیم تمام دنباله را به صورت یکجا به ترنسفورمر بدهیم تا به صورت موازی مدل آموزش ببیند.
مانند شبکه عصبی بازگشتی (RNN)، ترانسفورمرها برای مدیریت دادههای ورودی متوالی، مانند زبان طبیعی، برای کارهایی مانند ترجمه و خلاصه متن طراحی شدهاند. با این حال، برخلاف شبکه عصبی بازگشتیها، ترانسفورمرها لزوماً دادهها را به ترتیب پردازش نمیکنند. در عوض، مکانیسم توجه زمینه را برای هر موقعیتی در دنباله ورودی فراهم میکند. به عنوان مثال، اگر داده ورودی یک جمله زبان طبیعی باشد، ترانسفورمر نیازی به پردازش ابتدای جمله قبل از پایان ندارد. در عوض، زمینه ای را مشخص میکند که به هر کلمه در جمله معنا میبخشد. این ویژگی اجازه میدهد تا موازی سازی بیشتر از شبکه عصبی بازگشتیها باشد و بنابراین زمان آموزش را کاهش میدهد
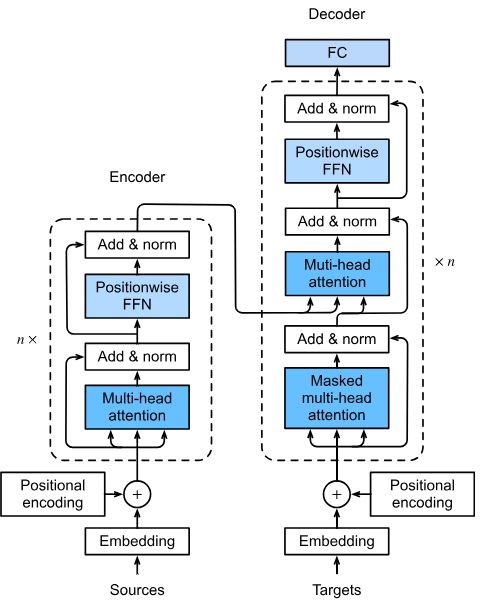
همانطور که در شکل زیر می بینید ترنسفورمر از دو قسمت تشکیل شده است: قسمت Encoder (سمت چپ) و قسمت Decoder (سمت راست). ترنسفورمر از دو لایه Encoder و Decoder تشکیل شده است که هر لایه N بار تکرار میشود. Encoder داده را یک جا میگیرد و برای ترتیب کلمات از positional encoding استفاده می شود. در گام بعدی عملیات multi head attention انجام شده و attention ها به دست میآید. یعنی اگر 500 کلمه داشته باشیم در این مرحله امتیاز تکتک این کلمهها محاسبه میشود. پس از محاسبه attentionها از یک لایه normalizer استفاده و نتیجه به یک feed forward وارد میشود. وظیفه feed forward خلاصهسازی و نرمالسازی بردارهایی است که multi head attention تولید میکند. این مراحل N بار تکرار شده و در مرحله N ام خروجی Encoder به Decoder داده میشود. Decoder به ورودیها یک شیفت به راست میدهد و هدفش این است که کلمه بعدی را پیشبینی کند. همچنین، در لایه آخر Decoder یک تابع softmax وجود دارد، تا احتمال کلمه بعدی محاسبه شود.
برای محاسبه attentionها، باید چند بردار زیر محاسبه شود:
- Query vector
- Key vector
- Value vector
در طول زمان این بردارها آپدیت و بهینه میشوند.
هدف از این دوره آموزشی:
هدف از این دوره آموزشی، آموزش سازوکار توجه در شبکه های عمیق است. در این دوره سازوکار توجه و شبکه های ترنسفورمری به صورت تئوری و عملی بحث و پیاده سازی می شود. همچنین، انواع مختلف الگوریتم های توجه توضیح داده می شود و پیاده سازی با زبانی ساده و قابل فهم انجام می شود. ابتدا یک مرور کامل روی برنامه نویسی پایتون و یادگیری ماشین و یادگیری عمیق انجام می شود. سپس تئوری سازوکار توجه مبتنی بر ترنسفورمر توضیح داده می شود. در نهایت، سازوکارهای توجه ترنسفورمری با زبان پایتون و کتابخانه کراس پیاده سازی می شوند. بدون شک یکی از بهترین دوره های هوش مصنوعی با زبان فارسی می باشد که با زبان ساده و روان توضیح داده شده است. امیدواریم که این آموزش از “بیگ لرن” هم مثل سایر آموزش ها مورد تایید و رضایت شما مخاطبان گرامی قرار گیرد.
بخش اول: مرور کامل پایتون
بخش دوم: مرور یادگیری ماشین/عمیق (عملی و تئوری)
بخش سوم: سازوکار توجه (Attention)
بخش چهارم: آموزش شبکه های ترنسفورمر (Transformers)
موارد مرتبط




نظرات
برای ثبت نقد و بررسی وارد حساب کاربری خود شوید.
قیمت 195,000 تومان


دکترای مهندسی کامپیوتر (گرایش هوش مصنوعی و رباتیکز) هستم. عمده فعالیت من در حوزه یادگیری عمیق، علم داده، پردازش تصویر و پردازش متن با زبان های برنامه نویسی پایتون و جاوا است.




دیدگاهها
هیچ دیدگاهی برای این محصول نوشته نشده است.